Données de santé : l’arbre StopCovid qui cache la forêt Health Data Hub
Le projet de traçage socialement “acceptable” à l’aide des smartphones dit StopCovid, dont le lancement était initialement prévu pour le 2 juin, a focalisé l’intérêt de tous.
Bernard Fallery, Université de Montpellier

Apple et Google se réjouissaient déjà de la mise en place d’un protocole API (interface de programmation d’application) qui serait commun pour de nombreux pays et qui confirmerait ainsi leur monopole. Mais la forte controverse qu’a suscitée le projet en France, cumulée au fait que l’Allemagne s’en est retirée et à l’échec constaté de l’application à Singapour, où seulement 20 % des utilisateurs s’en servent, annoncent l’abandon prochain de StopCovid.
“Ce n’est pas prêt et ce sera sûrement doucement enterré. À la française“, estimait un député LREM le 27 avril auprès de l’AFP.
Pendant ce temps-là, un projet bien plus large continue à marche forcée : celui de la plate-forme des données de santé Health Data Hub (HDHub).
Health Data Hub, la forêt qui se cache derrière l’arbre
Dès la remise du rapport Villani sur l’intelligence artificielle (IA) en mars 2018, le président de la République annonce le projet HDHub. En octobre de cette même année, une mission de préfiguration définit les traits d’un système national centralisé regroupant l’ensemble des données de santé publique, un guichet unique à partir duquel l’IA pourrait optimiser des services de reconnaissance artificielle et de prédiction personnalisée.
Mais l’écosystème de l’IA s’apprête aussi à franchir une nouvelle marche en obtenant l’accès à des données massives provenant des hôpitaux, de la recherche, de la médecine de ville, des objets connectés, etc., et à un marché massif de la santé (prestigieux et à valeur potentielle énorme dans la mesure où il pèse plus de 12 % du PIB). La France, avec son assurance maladie, et le Royaume-Uni, avec son National Health Service (NHS), font ici figure de test, puisque des données cohérentes et fiables y sont maintenues depuis des décennies : Amazon a déjà accès à l’API du NHS pour alimenter son assistant vocal, et Microsoft a déjà signé l’hébergement de toutes les données de santé françaises (stockage, gestion des logs et des annuaires, puissance de calcul et conservation des clés de chiffrement).
Le projet HDHub mené “au pas de charge”
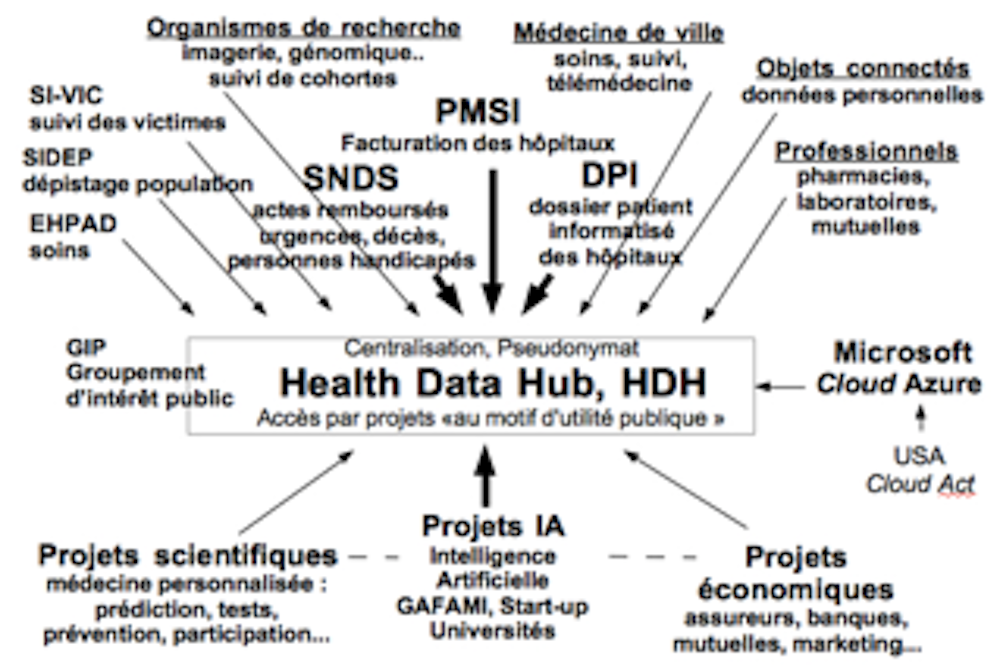 En novembre 2018, Stéphanie Combes est nommée cheffe de projet. Fin 2018, le choix de Microsoft est déjà acté (en “dispense de marché public”), alors même que la définition des principes de HDHub attendront juillet 2019 (dans la Loi Santé) et que ses missions ne seront définies qu’en avril 2020, par arrêté ministériel. La CNIL, malgré ses échanges avec Stéphanie Combes, continue à se poser de nombreuses questions.
En novembre 2018, Stéphanie Combes est nommée cheffe de projet. Fin 2018, le choix de Microsoft est déjà acté (en “dispense de marché public”), alors même que la définition des principes de HDHub attendront juillet 2019 (dans la Loi Santé) et que ses missions ne seront définies qu’en avril 2020, par arrêté ministériel. La CNIL, malgré ses échanges avec Stéphanie Combes, continue à se poser de nombreuses questions.
D’autres voix se sont inquiétées de la gestion si hâtive du projet (comme le Conseil national des barreaux, l’Ordre national des médecins ou encore un député LREM) ; des collectifs ont lancé des alertes argumentées, comme les professionnels de InterHop ou les entreprises du logiciel libre ; et certains médecins ont mis en ligne des vidéos exprimant leur révolte.
Health Data Hub, un cas d’école sur toutes les problématiques du numérique
Contourner l’arbre qui cache la forêt, c’est découvrir toute l’étendue des questions posées par la “transformation numérique” dans la société, et ici dans la santé.
Les questions politiques se cristallisent ici autour du choix de Microsoft, que Stéphanie Combes justifie très classiquement par l’urgence, sans publication des délibérations : “Microsoft était le seul capable de répondre à nos demandes. On a préféré aller vite, pour ne pas prendre de retard et pénaliser la France.”
C’est une question de politique nationale, déjà soulevée dans The Conversation France, puisqu’il s’agit de faire gérer un bien public par un acteur privé, et sans espoir de réversibilité. Mais aussi une question politique de souveraineté numérique européenne puisque cet acteur étasunien se trouve soumis au Cloud Act, loi de 2018 qui permet aux juges américains de demander l’accès aux données sur des serveurs situés en dehors des États-Unis.
Les questions techniques se révèlent ici dans un vif débat entre centralisation ou interopérabilité des bases de données. La centralisation définit des architectures de “défense en profondeur” avec des barrières successives par exemple dans le nucléaire ; dans le projet HDHub, cette défense est sous-traitée chez Microsoft.
Stéphanie Combes observe que “si l’on veut faire du traitement de données à cette échelle, on doit centraliser, c’est la seule solution“. À l’opposé, la vision technique des architectures de l’interopérabilité vise à “ne pas mettre tous ses œufs dans le même panier” : d’une part, la majorité des attaques ne viennent pas de l’extérieur mais de l’intérieur, avec un risque plus élevé en cas de centralisation, et d’autre part l’anonymat ne résiste pas à la ré-identification d’une personne par croisement de données.
Cette architecture décentralisée consiste alors à gérer les échanges en réseau entre des bases de données qui restent hétérogènes et entre des traitements distribués sur plusieurs serveurs, mais en intégrant ces échanges par des couches d’interfaces qui sont aujourd’hui standardisées et en Open source. À titre d’exemple, c’est une option qui a été choisie dans le projet eHop pour un groupe d’hôpitaux. Elle présente l’avantage de maintenir localement les compétences des ingénieurs et des soignants, nécessaires à la qualification des données de santé.
Les questions juridiques concernent ici le consentement et le secret médical. Les principes européens du RGPD organisent le consentement dès la conception des systèmes d’information (privacy by design) et par une culture de transparence interne dans les organisations (via le délégué à la protection des données). Les données des patients touchent bien sûr à leur intimité, mais la durée, le droit de retrait et surtout la finalité claire d’une utilisation de ces données, sont des principes intangibles fixés par la CNIL.
Stéphanie Combes a donné des perspectives sur ce point :
“Les données ne sont censées être stockées que durant la période de l’état d’urgence sanitaire. À sa fin, elles devront être détruites, SAUF SI un autre texte prévoit cette conservation lors de la mise en place finale du Health Data Hub.”
Dans la pratique, et sans compter les problèmes futurs de responsabilité individuelle du médecin, les patients pourraient être soumis à une rupture du secret médical, un principe juridique mais aussi une règle éthique qui fonde la confiance basée sur le serment d’Hippocrate. Une rupture de cette confiance présenterait bien sûr des risques en termes de santé publique.
Les questions économiques se cristallisent autour des enjeux de la transformation numérique. Les tenants du néo-libéralisme voient surtout dans le numérique une force de destruction créatrice : la dérégulation et le désengagement des États favorisent l’innovation disruptive et la croissance par des start-up. Au-delà du seul intérêt scientifique, un développement rapide de l’IA grâce aux GAFAMI, les six géants américains qui dominent le marché du numérique, peut donc être considéré comme relevant de “l’intérêt général”, une finalité introduite en 2019 dans la Loi santé.
À l’opposé, les tenants d’une politique économique alternative voient surtout dans le numérique une possibilité de gestion des communs numériques, en suivant les analyses de Elinor Ostrom : des ressources immatérielles non rivales, dont les règles d’accès et d’usage sont gérées par des communautés auto-organisées très diverses (par exemple, depuis Internet, en passant par Wikipedia et jusqu’à l’Open data, le logiciel libre ou les énormes bases scientifiques de type Protein Data Bank). Ceux qui partagent cette vision dénoncent l’idée de la séparation entre d’une part la qualification des données médicales, qui se fait grâce à un long travail de collecte et de tri financé par le secteur public et soumis aux traités de libre circulation des données, et d’autre part la valorisation de ces données, avec une marchandisation de la santé par le secteur privé que protègent les traités sur les brevets.
Le contrôle des “data santé” vu par les penseurs d’hier et d’aujourd’hui
La question sociale du contrôle sanitaire de nos comportements ne peut pas être analysée sans les concepts forgés par les sociologues. Michel Foucault a décrit le passage progressif à la société disciplinaire en utilisant les concepts de “biopolitique” (qui porte sur les formes d’exercice du pouvoir sur les corps) et de “gouvernementalité” (qui associe gouvernement et rationalité, dans des technologies du gouvernement des individus et de soi, pour assurer l’autodiscipline : hier déjà, le confinement, l’école, l’hôpital, les statistiques et maintenant les panoptiques du drone et du bracelet).
Gilles Deleuze a décrit un nouveau passage vers la société de contrôle par le collier électronique, avec les concepts de “langage numérique” d’accès à la réalité. Alors que Kafka a forgé la notion d’“atermoiement illimité” : il ne s’agit plus de discipliner et d’ordonner, mais de contrôler en gérant tout désordre.
Aujourd’hui, des sociologues comme A. Rouvroy ou D. Quessada montrent un prochain passage à la société des traces avec les concepts de gouvernementalité algorithmique (qui va au-delà d’une maîtrise du probable ; il s’agit d’une maîtrise du potentiel lui-même, pour “ajuster” nos comportements) et de sousveillance, qui n’est plus une sur-veillance, mais une sous-veillance par un quadrillage discret, immatériel et omniprésent de tous les types de traces que nous laissons, comme nos signaux, nos productions, nos empreintes, nos passages et nos liens…![]()
Bernard Fallery, Professeur émérite en systèmes d’information, Université de Montpellier
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.